Introduction to Bayesian methods
Introduction to Bayesian methods:
1. Bayesian way of thinking:
A man is running. Why? Some of the possible explanations are (1) this man is in hurry, (2) this man is running, (3) this man just spotted a dragon, and (4) this man always runs. There are three principles in Bayesian way of thinking which we can use to conclude which of these explanations are the most reasonable.
These principles are:
1. Use the prior knowledge on the problem - there is no dragon.
2. Choose the answer that explains the data the most - the man is not wearing the runner.
3. Avoid making extra assumptions - crude to think that any man always run.
The answer number "1. this man is in hurry" should be chosen following this principles.
2. Review of probability:
Checklists are:
1. What is the probability?
2. What are random variables?
3. What is the probability mass function (PMF)?
4. What is the probability density function (PDF)?
5. What does it mean for the random variables X and Y to be independent? Joint Vs Marginal.
6. What is the conditional probability?
7. What is the joint probability?
8. What is the chain rule for the joint probability?
9. What is the sum rule? What is marginalization?
10. What is the Bayes theorem? What are the posterior, the likelihood, the prior and the evidence?
3. Bayesian approach to statistics:
(a) Frequentist approach Vs (b) Bayesian appraoch
1. (a) the parameters of the model is fixed and the data is random.
(b) the parameters of the model is random and the data is fixed.
2. (a) the number of parameters is smaller than the data.
(b) the number of parameters does not have to be smaller than the data.
3. (a) Use the maximum likelihood principle to find the parameters.
(b) Use the Bayes theorem to find the parameters.
4. (a) Assume the uncertainty to be objective.
(b) Assume the uncertainty to be subjective.
To explain the point 3 (b), the Bayesian approach would use the probability of the parameters given the training data set (Xtr,ytr) and predict using the conditional probability of ytest given the Xtest, the training data set (which is marginalized with the parameters).
The Bayesian approach can do good with regularizing (by choosing specific priors) and online learning.
4. How to define a probabilistic model:
The probabilistic model can be defined as the Bayesian network (different from the Bayesian Neural Network) where node is the random variables and edges are where it has direct impact on..

The model can be computed using the BN by looking into the joint probability over all the variables. This joint probability equals the product of the conditional probabilities of all the random variables given its corresponding parents. See the definition of parents given below.


Naive Bayes classifier can also be written using the probabilistic model. Here, a random variable c representing the class, has impacts on each individual features. So the joint probability takes the following form shown in the equation below.

It can also be written in plate notation where we have the random variable c representing the classes and it has edges on the features inside the plate with N (meaning there are N different features f).

Can BN have directed cycles? The answer is nope. We cannot have the interdependent variables and in those cases, use Markov Random Fields or join random variables into one single random variable.
5. Linear regression:
The univariate normal distribution is explained from slide 1 to 3. The univariate normal distribution has the probability density function as shown in slide 1, and is typically governed by two parameters the mean and the variance. The normalization term ensures that the integral of the distribution is 1.
In the multivariate normal distribution we have the vector of mu and the matrix of covariance. Again, the normalization term ensures that the integral of the distribution is 1. D is the dimension of the covariance matrix. The number of parameters vary as shown in the slide where importantly the first FULL case is still a symmetrical case. It is just badly explained.
In linear regression we want to find the red line that has minimum distance (black line) to the blue points which are the data. This line can be found with so called the least squares problem and is formulated in slide 6. How could we formulate the least squares problem in Bayesian view? We construct the probabilistic model with weights, data and target. As we are not interested in modelling the probability distribution of the data (data is fixed) the presented probabilistic modelling simplifies to the conditional probability of the weights w and the target y given the data. Assume the normal distributions as shown in the slide 7.
Then we find that the conditional probability of the model given the data and the target (which we want to maximize for the model parameters) is proportional to the joint probability of the weight and the target given the data. This would mean that maximizing this probability is equivalent to finding the posterior distribution for the model parameters. See the mathematical derivations in the slides. The final form is the L2 regularized linear regression.
6. MLE estimate of the Gaussian mean:
The document below summarizes the maximum likelihood estimate in both univariate and multiunivariate cases. In summary the maximum likelihood estimate for parameters is the value of the parameters that maximizes the likelihood (the conditional probability of the data over the parameters). Note that this likelihood may not be the probability as its integral with respect to the parameters may not equal to one.
1. Bayesian way of thinking:
A man is running. Why? Some of the possible explanations are (1) this man is in hurry, (2) this man is running, (3) this man just spotted a dragon, and (4) this man always runs. There are three principles in Bayesian way of thinking which we can use to conclude which of these explanations are the most reasonable.
These principles are:
1. Use the prior knowledge on the problem - there is no dragon.
2. Choose the answer that explains the data the most - the man is not wearing the runner.
3. Avoid making extra assumptions - crude to think that any man always run.
The answer number "1. this man is in hurry" should be chosen following this principles.
2. Review of probability:
Checklists are:
1. What is the probability?
2. What are random variables?
3. What is the probability mass function (PMF)?
4. What is the probability density function (PDF)?
5. What does it mean for the random variables X and Y to be independent? Joint Vs Marginal.
6. What is the conditional probability?
7. What is the joint probability?
8. What is the chain rule for the joint probability?
9. What is the sum rule? What is marginalization?
10. What is the Bayes theorem? What are the posterior, the likelihood, the prior and the evidence?
3. Bayesian approach to statistics:
(a) Frequentist approach Vs (b) Bayesian appraoch
1. (a) the parameters of the model is fixed and the data is random.
(b) the parameters of the model is random and the data is fixed.
2. (a) the number of parameters is smaller than the data.
(b) the number of parameters does not have to be smaller than the data.
3. (a) Use the maximum likelihood principle to find the parameters.
(b) Use the Bayes theorem to find the parameters.
4. (a) Assume the uncertainty to be objective.
(b) Assume the uncertainty to be subjective.
To explain the point 3 (b), the Bayesian approach would use the probability of the parameters given the training data set (Xtr,ytr) and predict using the conditional probability of ytest given the Xtest, the training data set (which is marginalized with the parameters).
The Bayesian approach can do good with regularizing (by choosing specific priors) and online learning.
4. How to define a probabilistic model:
The probabilistic model can be defined as the Bayesian network (different from the Bayesian Neural Network) where node is the random variables and edges are where it has direct impact on..

The model can be computed using the BN by looking into the joint probability over all the variables. This joint probability equals the product of the conditional probabilities of all the random variables given its corresponding parents. See the definition of parents given below.


Naive Bayes classifier can also be written using the probabilistic model. Here, a random variable c representing the class, has impacts on each individual features. So the joint probability takes the following form shown in the equation below.
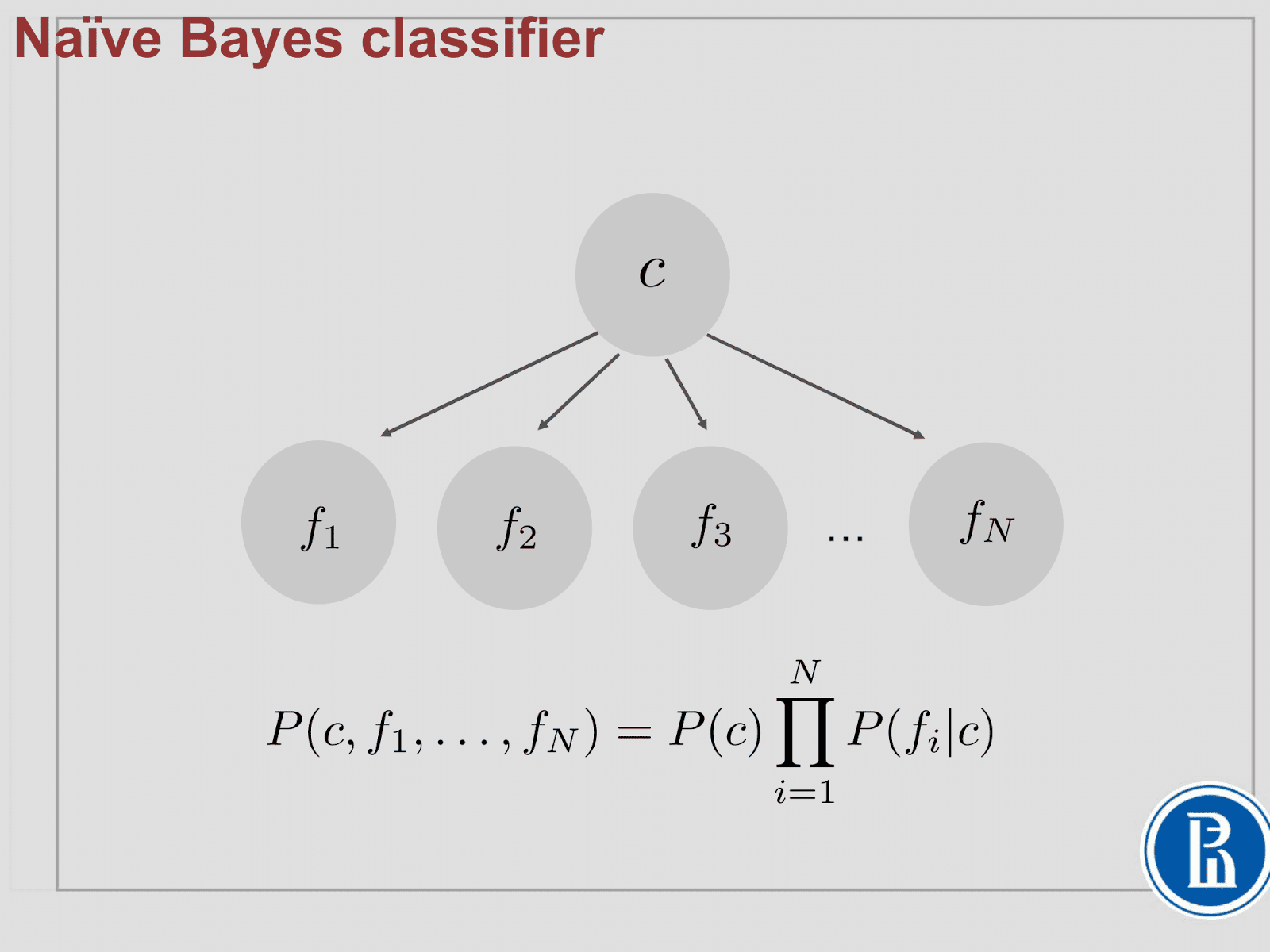
It can also be written in plate notation where we have the random variable c representing the classes and it has edges on the features inside the plate with N (meaning there are N different features f).

Can BN have directed cycles? The answer is nope. We cannot have the interdependent variables and in those cases, use Markov Random Fields or join random variables into one single random variable.
5. Linear regression:
The univariate normal distribution is explained from slide 1 to 3. The univariate normal distribution has the probability density function as shown in slide 1, and is typically governed by two parameters the mean and the variance. The normalization term ensures that the integral of the distribution is 1.
In the multivariate normal distribution we have the vector of mu and the matrix of covariance. Again, the normalization term ensures that the integral of the distribution is 1. D is the dimension of the covariance matrix. The number of parameters vary as shown in the slide where importantly the first FULL case is still a symmetrical case. It is just badly explained.
In linear regression we want to find the red line that has minimum distance (black line) to the blue points which are the data. This line can be found with so called the least squares problem and is formulated in slide 6. How could we formulate the least squares problem in Bayesian view? We construct the probabilistic model with weights, data and target. As we are not interested in modelling the probability distribution of the data (data is fixed) the presented probabilistic modelling simplifies to the conditional probability of the weights w and the target y given the data. Assume the normal distributions as shown in the slide 7.
Then we find that the conditional probability of the model given the data and the target (which we want to maximize for the model parameters) is proportional to the joint probability of the weight and the target given the data. This would mean that maximizing this probability is equivalent to finding the posterior distribution for the model parameters. See the mathematical derivations in the slides. The final form is the L2 regularized linear regression.
6. MLE estimate of the Gaussian mean:
The document below summarizes the maximum likelihood estimate in both univariate and multiunivariate cases. In summary the maximum likelihood estimate for parameters is the value of the parameters that maximizes the likelihood (the conditional probability of the data over the parameters). Note that this likelihood may not be the probability as its integral with respect to the parameters may not equal to one.

Thank you :)
ReplyDelete