Notes on "Focal Loss for Dense Object Detection" (RetinaNet)
Focal Loss for Dense Object Detection by Lin et al (2017)
The central idea of this paper is a proposal for a new loss function to train one-stage detectors which works effectively for class imbalance problems (typically found in one-stage detectors such as SSD). The authors also introduce RetinaNet based on the proposed loss function which outperforms the state-of-the-art detection algorithms including the two-stage detectors.
Focal loss function:
pt is defined as p if y = 1 and p-1 otherwise. In this way, CE(pt) is the cross entropy where p is the probability score. As shown below, the cross entropy is denoted blue (gamma = 0). By adding the factor (see the focal loss FL(pt)) the loss function computes smaller value for the well classified examples and puts more focus on hard and misclassified eamples. In this way the easy background examples are dealt with, which enables the training of highly accurate desne object detection algorithms. Just like alpha-cross entropy is the common way of dealing with class imbalance (importance of positive and negative examples) the alpha term is added to the FL(pt) in practice to acheive better performance. If y = 1 then alpha_t = alpha while alpha_t = 1-alpha otherwise. Alpha is defined to be between 0 and 1.

RetinaNet:
RetinaNet is a single unified network composed of a backbone network and two task-specific subnetworks. The backbone is responsible for computing a convlutional feature map over an entire input image and is an off-the-self convolutional network (uses ResNet in this paper but can be somethingelse like VGG or inception). On the otherhand, the first subnet performs convolutional object classification on the backbone's output while the second subnet performs convlutional bounding box regression.
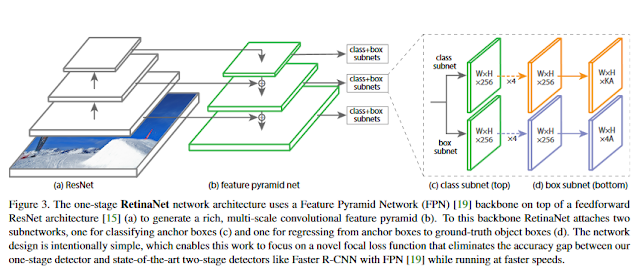 Additionally, the following points address some details on the network architecture:
Additionally, the following points address some details on the network architecture:
Q&A: (TOBEADDED)
The central idea of this paper is a proposal for a new loss function to train one-stage detectors which works effectively for class imbalance problems (typically found in one-stage detectors such as SSD). The authors also introduce RetinaNet based on the proposed loss function which outperforms the state-of-the-art detection algorithms including the two-stage detectors.
Focal loss function:
pt is defined as p if y = 1 and p-1 otherwise. In this way, CE(pt) is the cross entropy where p is the probability score. As shown below, the cross entropy is denoted blue (gamma = 0). By adding the factor (see the focal loss FL(pt)) the loss function computes smaller value for the well classified examples and puts more focus on hard and misclassified eamples. In this way the easy background examples are dealt with, which enables the training of highly accurate desne object detection algorithms. Just like alpha-cross entropy is the common way of dealing with class imbalance (importance of positive and negative examples) the alpha term is added to the FL(pt) in practice to acheive better performance. If y = 1 then alpha_t = alpha while alpha_t = 1-alpha otherwise. Alpha is defined to be between 0 and 1.

RetinaNet:
RetinaNet is a single unified network composed of a backbone network and two task-specific subnetworks. The backbone is responsible for computing a convlutional feature map over an entire input image and is an off-the-self convolutional network (uses ResNet in this paper but can be somethingelse like VGG or inception). On the otherhand, the first subnet performs convolutional object classification on the backbone's output while the second subnet performs convlutional bounding box regression.
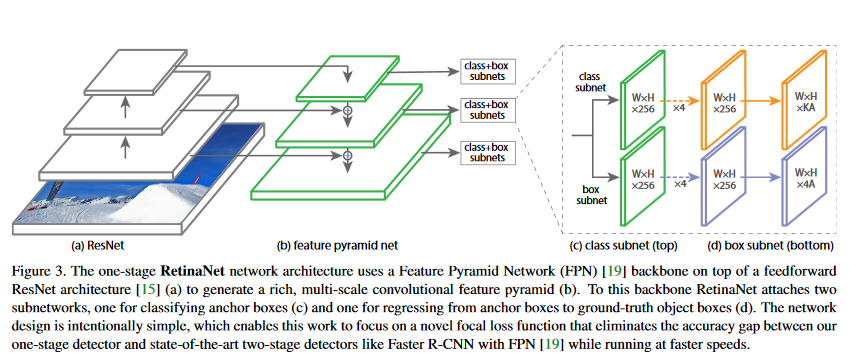
- Feature Pyramid Network as backbone.
- Anchor choices similar to R-CNN.
- Classification and regression subnets.
Q&A: (TOBEADDED)

Comments
Post a Comment